基本概念
视觉运行设计域 / 场景表征
-
运行设计域 ODD (Operational Design Domain)
SAE J3016 将 ODD 定义为“特定驾驶自动化系统或其功能专门设计的运行条件,包括但不限于环境、地理和时间限制,和/或某些交通或道路特征的存在或缺失。”
简单来说,ODD就是要定义好在哪些工况下是能够自动驾驶的,脱离了这些工况,自动驾驶就不能保证工作。任何一台自动驾驶车辆,都必须有一定限定的工况。而这个工况可以很宽泛,也可以很精准,并决定了自动驾驶车辆能胜任什么样的场景。比如,一台车的自动驾驶系统只能在高速上使用,它可以自动保持车道、自动超车、自动跟车、自动让行、自动通过ETC、自动上下匝道等,但到了城市里就无法完全自动驾驶。同时,要确保自动驾驶测试和验证是完整的,至少需要确保ODD所有方面已经通过确保系统安全运行,或通过确保系统能够识别超出ODD 的范围。
在工信部发布的《GBT 汽车驾驶自动化分级》推荐性国家标准中,ODD是设计时确定的驾驶自动化功能的本车状态和外部环境。
场景表征 & 图像编码
P.S. 图像编码部分并非本人负责,这里只总结一下相关的思路
首先,如果我们已经有了标注信息足够全面的数据集,那么无需再对场景数据进一步编码,只需要套用标注的信息表征场景即可。
但这样的数据集有两个问题:
- 需要的人力资源大。面对现实世界纷繁复杂的交通状况,根本没有精力去为大量交通数据标注信息;
- 不同领域标注的重点信息乃至标注的信息格式也不同。这导致无法使用多个数据集训练同一个模型;或者训练出来的模型泛化性不高。
所以,要考虑在缺少标注乃至没有标注的情况下,应该如何提取图像的特征,进而形成涵盖所有场景特征的离散特征空间。
(半监督) 图像编码:VGG 网络
可以采用“将图像编码”的思路,提取图像的特征,并将其压缩到更小维度的 latent space 中。
用于编码图像 (压缩图像 / 提取图像特征) 的 NN 依旧需要人工标记的场景数据集训练。
-
VGG-16 (项目中采用的网络结构)
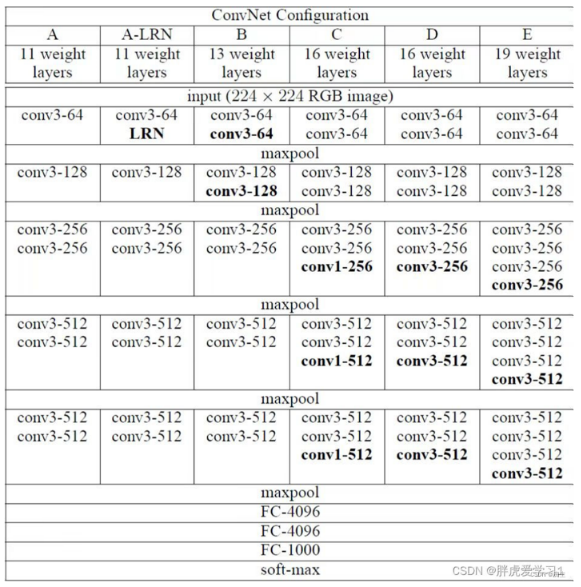
✨ 项目中只是采用了 VGG-16 网络的卷积池化层,并没有采用最后的三步全连接以及一步 softmax 层,取而代之的是一个平均池化层:
224 * 224 * 3 -> [conv3-64] * 2 -> [maxpool] ->
112 * 112 * 64 -> [conv3-128] * 2 -> [maxpool] ->
56 * 56 * 128 -> [conv3-256] * 3 -> [maxpool] ->
28 * 28 * 256 -> [conv3-512] * 3 -> [maxpool] ->
14 * 14 * 512 -> [conv3-512] * 3 -> [maxpool] ->
7 * 7 * 512 -> [avgpool] ->
1 * 1 * 512为什么这么做呢?
因为我们只需要图像在 latent space 中编码过的信息,并不需要执行某种分类操作,也就不需要额外的几个全连接层统合图像的特征,更不需要 softmax 层生成归一化概率。
最终采用 average pool 降维而不是 max pool,也是为了尽可能多地保留图片特征。
P.S. 尚未尝试将 average pool 更改为
kernel=7, channel=512的卷积层效果如何。P.P.S 注意到最终每一张图片 (每一个场景数据点) 都对应着深度为 512 的向量。而 Apolloscape 的原始交通场景数据集中有 5773 个样本,说明最终形成的特征空间 (编码后的场景空间) 足有 5773 * 1 * 512 之大。这已经堪称维度灾难,必须要采用某些方法降维处理。
图像自编码:AE & VAE
图像自编码技术是无监督生成模型的基础,被普遍使用于降维学习、特征学习以及图像生成等应用,主要包括自编码器(AE)和变分编码器(VAE)。
此二种编码器的主要思路均为:原始图像 → 编码器 → latent space representation → 解码器 → 生成的与原始图像相近的图像。优化目标大致为:使得生成图像与原始图像最接近。
注意到图像自编码过程会在 latent space 中表示原始图像,那么我们便可以利用该空间作为场景图像的编码,也就是作为场景表征。
能够使用 latent space 的另外一个原因还在于,既然解码器能够根据该 latent space representation 来 (eventually) 生成和原始图像相似乃至相同的新图像,说明该 latent space rep 已经有了足够多原始图像的信息。而且 latent space 往往都是降维表示的,所以自然而然便产生了“使用图像自编码过程中间的 latent space rep 作为我们所需要的图像编码 / 场景表征”的想法。
图像自编码:DRIT 网络
参考:DRIT:Diverse image-to-image translation via disentangled representations 论文阅读-CSDN博客
DRIT 网络将图像表示为两个 latent space representation:代表图像画面内容的 content space,以及代表图像画面属性 (风格 / 感觉 / 样式…) 的 attribute space;而且,这两个 latent space 之间是无耦合 (disentangled) 的。
应用到本项目中来,我们或许可以将“是否有雾霾”作为每个场景的 attribute,场景画面自然作为 content。这样不仅可以利用 DRIT 的两种编码器 (attribute encoder & content encoder) 的编码结果作为场景表征,更可以利用 DRIT 生成雾霾 / 去雾图像作为新的场景数据。
上述两种无监督的图像自编码方式依旧有“特征空间维度过高”的问题。
将场景的特征空间降维:主成分分析法线性降维 (无监督方法)
使用 PCA,在较大程度保留原特征空间的各个特征的情况下,将其降维。
由于PCA只需要通过特征值分解来实现数据降维,因此是一种无监督的降维方法。当协方差矩阵维数较高时,也可以通过奇异值分解(SVD)的方法获取PCA的解,可以明显地降低计算复杂度。
“在场景那离散、巨大的特征空间中搜索”
用于在特征空间中搜索的 NN 结构:长短时记忆网络 LSTM
111
场景样本检索 & 重排序
场景样本检索本质上就是图像检索问题,不同于单一的检索任务,本工作需要实现场景级的图像集合检索算法以支持搜索和预测框架的迭代,目标是找到具有相同场景的最差性能样本集。依赖于图像检索算法实现上层场景实例匹配任务,本文的场景样本检索更加关注于在保证 top-k 精度的同时,样本间的场景关联性要足够的强,对于对应场景表征具有较好的代表能力。
❓ 场景样本检索得到的 k 近邻场景 (场景实例) 和场景空间采样得到的场景特征是如何联系起来的?
使用场景空间采样得到的场景特征作为 probe 输入检索算法得到 k 近邻场景?还是使用场景样本检索得到的一些最差感知场景优化 LSTM 的参数?(应该不是后者……)
搜索过程大致为:LSTM 模型在场景的离散特征空间中搜索得到一系列可能的最差感知场景特征 → 将这些特征作为 query 输入场景样本检索算法,每个特征将对应检索得到的一组相同场景的样本 → 将所有样本交给场景匹配器,检测是否匹配最差感知场景,若匹配……
为了解决理想假设对搜 索方法泛用性和应用价值的限制,本文通过多种场景表征构建搜索空间,提出在搜索 框架中融入重排序技术来进一步提高匹配样例集的内部场景一致性,以改进场景样本 的匹配性能,并增加了实例集判别器来判断场景表征和对应场景实例集是否有效命中, 避免场景空间数据稀疏导致的强制匹配出现。